협업 필터링과 추천 시스템으로 내일 뭐 먹을지 결정해보기
Collaborative Filtering and Recommendation System
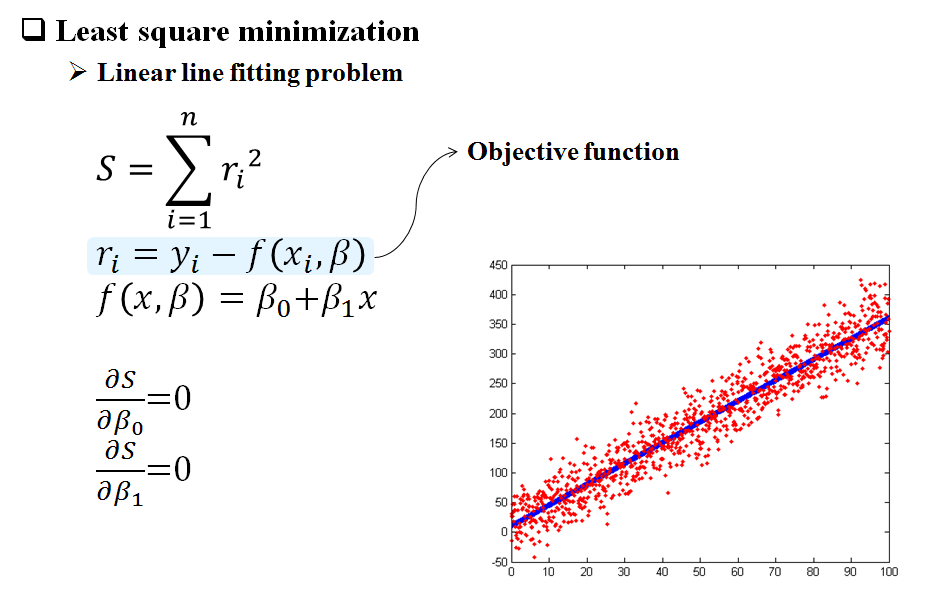
한글로 적어 놓고 나니 왠지 어색합니다. 협업 필터링(Collaborative Filtering)과 추천 시스템(Recommendation System)은 밀접한 관련이 있고, 우리가 모르는 사이에 매일 이것을 이용하고 있습니다. 실제로 Amazon에서 구매하는 물건의 약 35%가 추천으로부터 발생하고, Netflix의 영화 대여도 2/3 정도가 추천에 의해서 발생한다고 알려져 있습니다. 한국에서도 ‘와챠’라는 모바일 앱이 개인화된 추천 서비스를 제공함으로써 기존의 영화 리뷰 시장을 뒤흔들었습니다. 이 글에서는 추천 시스템 중에서 협업 필터링의 개념을 이용해서 ‘내일 뭐 먹을까?’를 결정해보는 간단한 예시를 통해 접근하고자 합니다.여기에서도 SVD를 적용합니다. SVD는 singular value가 큰 순서로 정렬되는 형태이므로, 중요한 정보를 압축할 수 있는 특성을 가진다는 것을 알고 있다면, Low-rank approximation으로 분류를 하는데 활용할 수 있다는 것도 생각해 볼 수 있습니다. 다시 말하면 eigenvalue가 큰 것들은 어떤 자료에서 중요한 의미를 지니는데, 그에 해당되는 eigenvector들은 모두 orthogonal합니다. orthogonal하다는 말은 직교한다는 말하고 비슷한데, 그릴 수 없는 3차원을 넘어가는 다차원에 대해서도 일반화된 개념입니다. 내적이 ‘0’이므로 서로 겹치는 부분이 없습니다. 어떤 자료를 SVD한다는 말은 결국 중요한 의미를 지니는 eigenvector공간으로 재 투영한 값들로 재구성한다는 의미로 해석하면 될 것 같습니다.
예를 들자면, 어느 학교의 학생에 대한 정보가 몸무게, 손가락 길이, 키로 각각 주어진다고 가정해보겠습니다. 그러면 3차원 공간에 데이터를 그려볼 수 있습니다. (1,0,0)(0,1,0)(0,0,1)-x, y, z-몸무게, 손가락 길이, 키를 기저 벡터로 하는 공간에 그리는 겁니다. 그런데, 만약에 키가 모두 비슷한 학생들만 다니는 학교라고 하면 z축은 별로 의미가 없어 집니다. x-y평면에 투영해서 봐도 3차원 공간의 데이터와 별로 손실이 없을 수 있다는 의미입니다.
추천 시스템에 활용하는 간단한 예시를 들어보겠습니다.
어떤 모임에 4명의 사람이 있었는데, 새로운 사람이 들어온 경우에 그 사람이 어떤 성향을 가지는 사람인지 판단하고 메뉴를 추천해주는 것을 생각해 볼 수 있습니다. 아래 표와 같은 정보가 주어진다고 가정해보겠습니다.
Korean Cuisine
|
Pizza
|
Hamburger
|
Chinese Cuisine
|
|
A
|
9
|
2
|
1
|
8
|
B
|
8
|
5
|
6
|
10
|
C
|
7
|
9
|
8
|
9
|
D
|
2
|
3
|
4
|
8
|
새로운 멤버 E와 식사를 하러 가야 하는데, 그날 마침 한국음식과 햄버거 중에 결정해야 하는 상황이라면 E는 어떤 음식을 더 좋아할까요?
Korean
Cuisine
|
Pizza
|
Hamburger
|
Chinese
Cuisine
|
|
A
|
9
|
2
|
1
|
8
|
B
|
8
|
5
|
6
|
10
|
C
|
7
|
9
|
8
|
9
|
D
|
2
|
3
|
4
|
8
|
E
|
?
|
9
|
?
|
7
|
SVD를 이용한 Low-rank approximation으로 추정해볼 수 있습니다. Rank 3으로 줄이면 아마도 한국음식, 피자, 햄버거와 비슷한 방향을 가지는 기저 벡터 공간에 재 투영될 것을 예측할 수 있습니다. 다음 예시를 참고하여 주시기 바랍니다.
협업 필터링 예제
E가 평가를 하지 않은 빈 곳에 대해서 평균으로 채우고 Low-rank approximation을 수행해보면 이 사람은 아마도 햄버거를 더 좋아하는 사람인 것 같습니다.
E가 평가를 하지 않은 빈 곳에 대해서 평균으로 채우고 Low-rank approximation을 수행해보면 이 사람은 아마도 햄버거를 더 좋아하는 사람인 것 같습니다.
실제 시스템에서는 고려해야 할 사항이 훨씬 더 많을 것입니다. 왜냐하면 SVD의 연산 복잡도는 선형으로 증가하지 않기 때문에 100만명의 회원이 있을 경우에 간단한 방법으로 해결할 수 없을 것입니다. 의도적으로 데이터에 손상을 가하려는 사람들(평점을 일부로 높게 주거나 낮게 주는 사람들)이 있을 수도 있고 개인적인 성향에 따라 평점이 후한 사람도 있고 그렇지 않은 사람도 있을 것입니다.


.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)








.jpg)



{kind=link}